2.5 KiB
Allowing reparted Pods to use S3 storage
As a first way to transfer data from one processing node to another we have implemented the mechanics that allow a pod to access a bucket on a S3 compatible server which is not on the same kubernetes cluster.
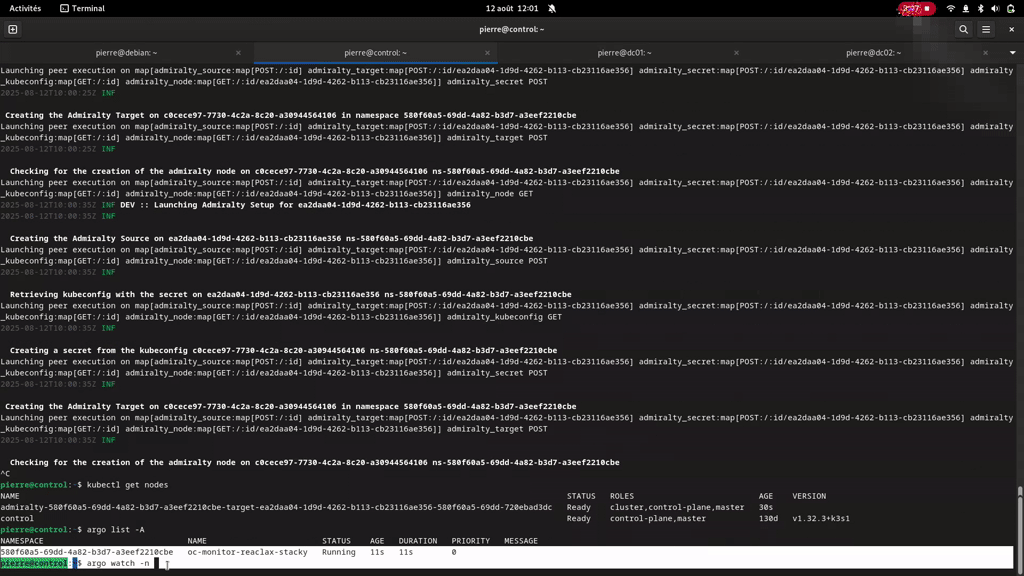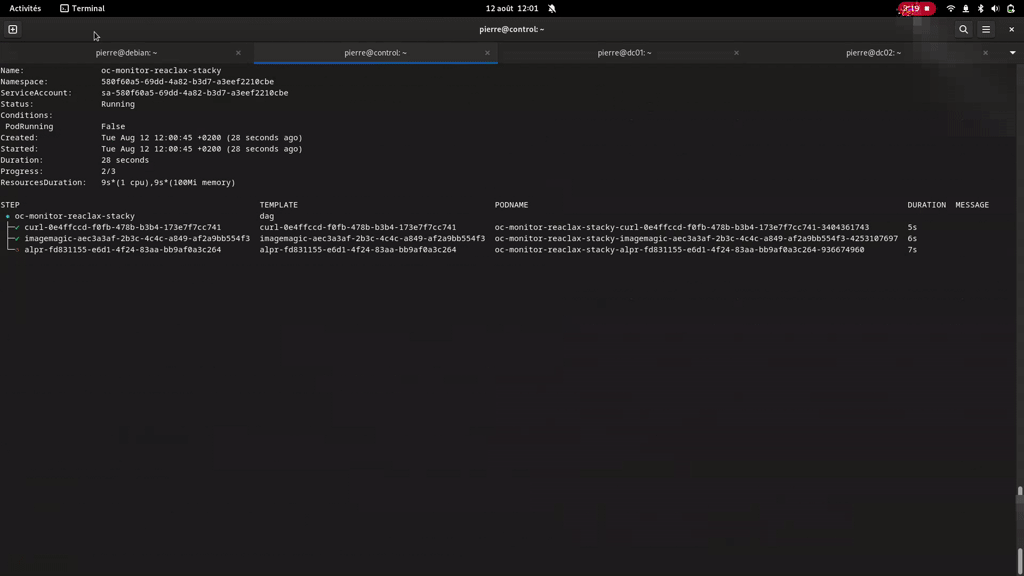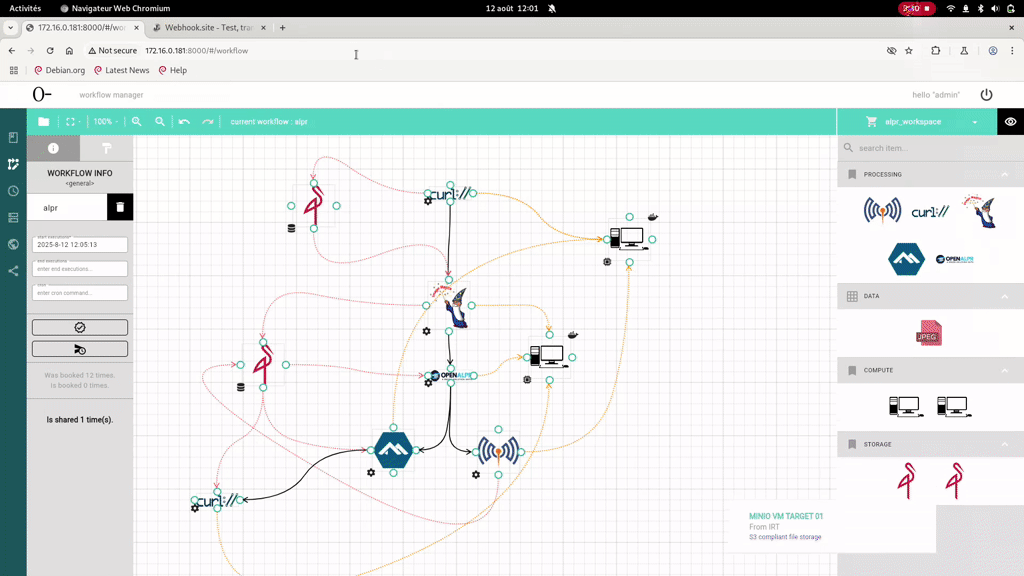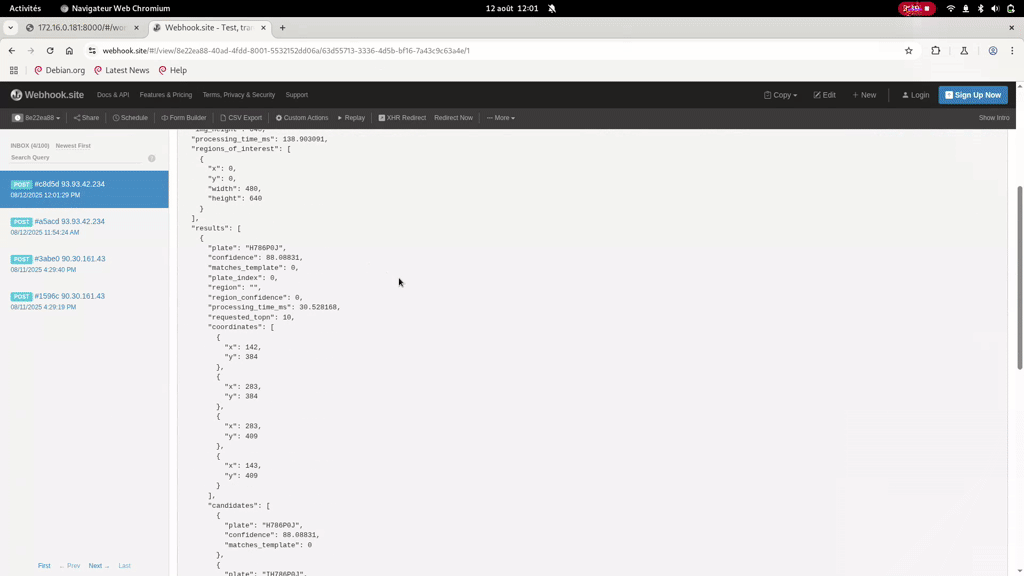
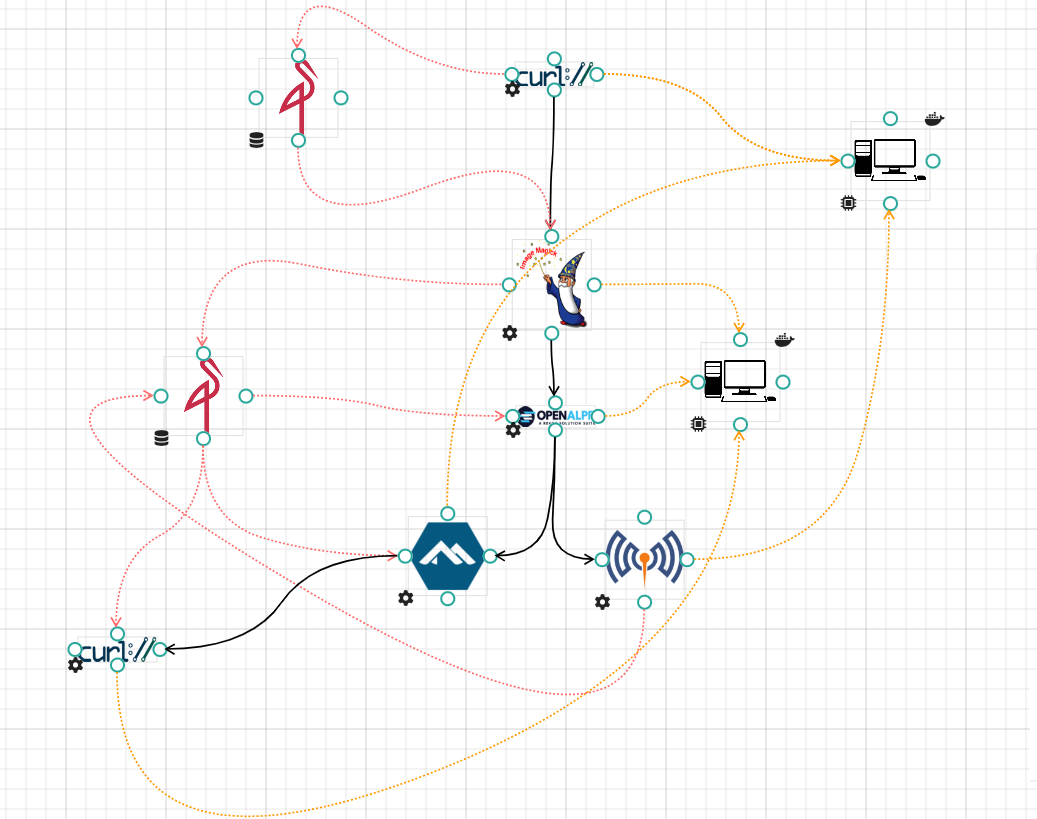
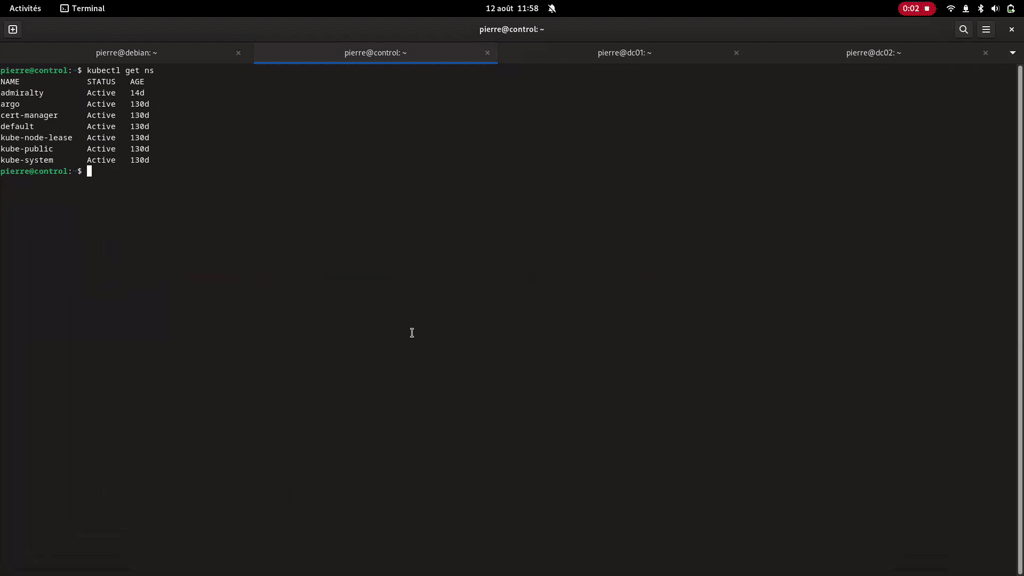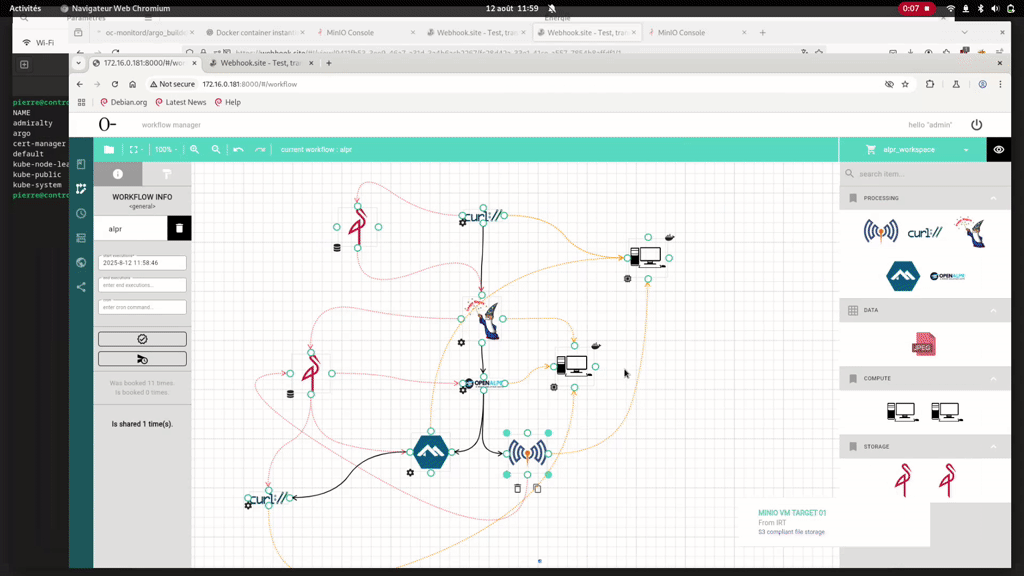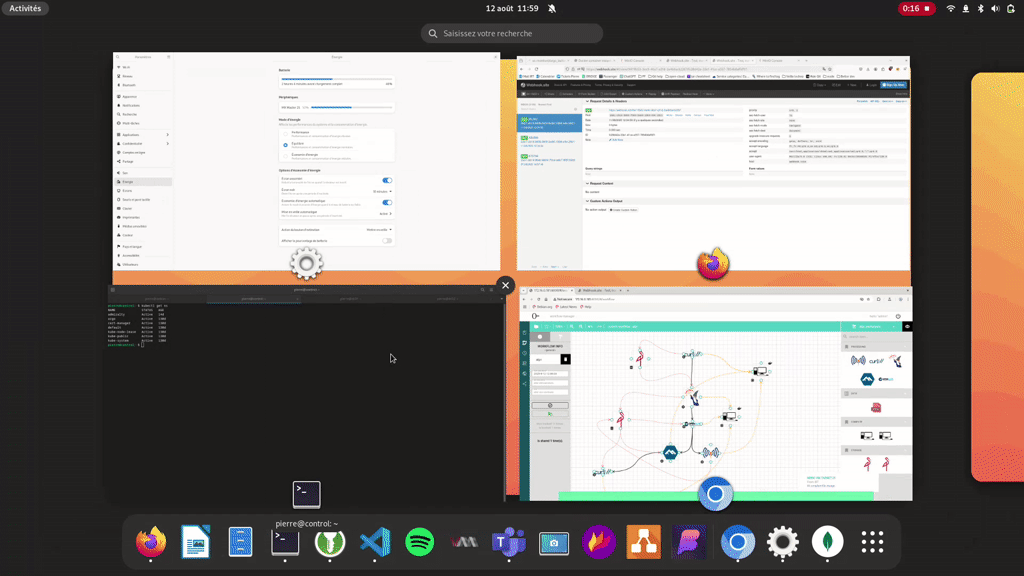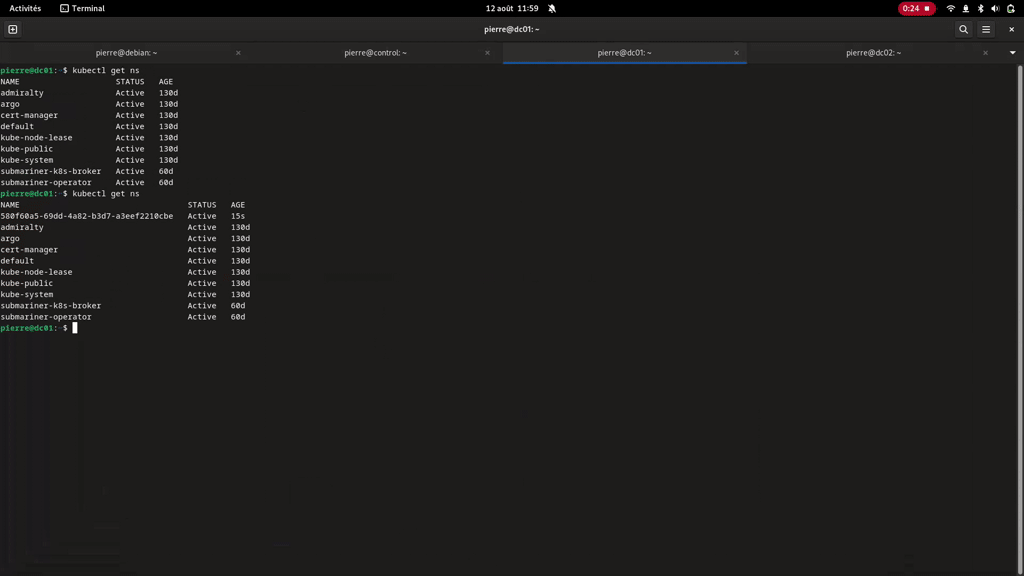
For this we will use an example Workflow run with Argo and Admiralty on the node Control, with the curl and mosquitto processing executing on the control node and the other processing on the Target01 node. To transfer data we will use the S3 and output/input annotations handled by Argo, using two Minio servers on Control and Target01.
When the user launches a booking on the UI a request is sent to oc-scheduler, which :
- Check if another booking is scheduled at the time requested
- Creates the booking and workflow executions in the DB
- Creates the namespace, service accounts and rights for argo to execute
We added another action to the existing calls that were made to oc-datacenter.
oc-scheduler retrieves all the storage ressources in the workflow and for each, retrieves the computing ressources that host a processing ressource using the storage ressource. Here we have :
-
Minio Control :
- Control (via the first cURL)
- Target01 (via imagemagic)
-
Minio Target01 :
- Control (via alpine)
- Target01 (via cURL, openalpr and mosquitto)
If the computing and storage ressources are on the same node, oc-scheduler uses an empty POST request to the route and oc-datacenter create the credentials on the S3 server and store them in a kubernetes secret in the execution's namespace.
If the two ressources are in different nodes oc-scheduler uses a POST request which states it needs to retrieve the credentials, reads the response and call the appopriate oc-datacenter to create a kubernetes secret. This means if we add three nodes
- A from which the workflow is scheduled
- B where the storage is
- C where the computing is
A can contact B to retrieve the credentials, post them to C for storage and then run an Argo Workflow, from which a pod will be deported to C and will be able to access the S3 server on B.
Final
We can see that the different processing are able to access the required data on different storage ressources, and that our ALPR analysis is sent to the mosquitto server and to the HTTP endpoint we set in the last cURL.